

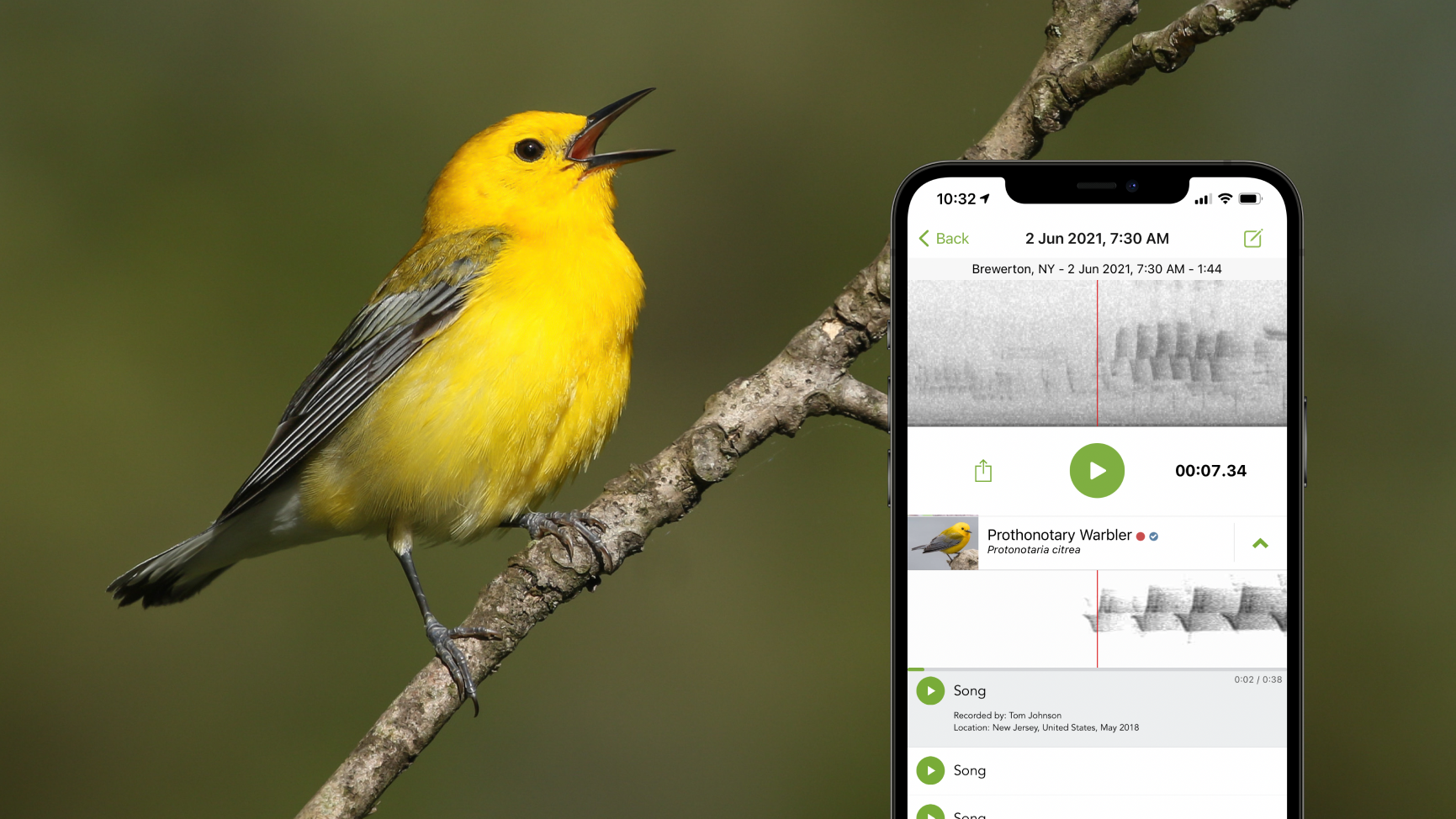
What is Sound ID?
Today we announced one of our biggest breakthroughs—Sound ID, a new feature in the Merlin Bird ID app—and a major leap forward in sound identification and machine learning to date. Sound ID lets people use their phone to listen to the birds around them, and see live predictions of who’s singing. Currently, Merlin can identify 458 bird species in the U.S. and Canada based on their sounds (with more species and regions coming soon). Sound ID runs on your device, without requiring a network connection. Download it today for free and test it out in your own backyard! If you happen to be located in the Northeastern United States you can test out Sound ID on the audio below which was recorded in New Hampshire.
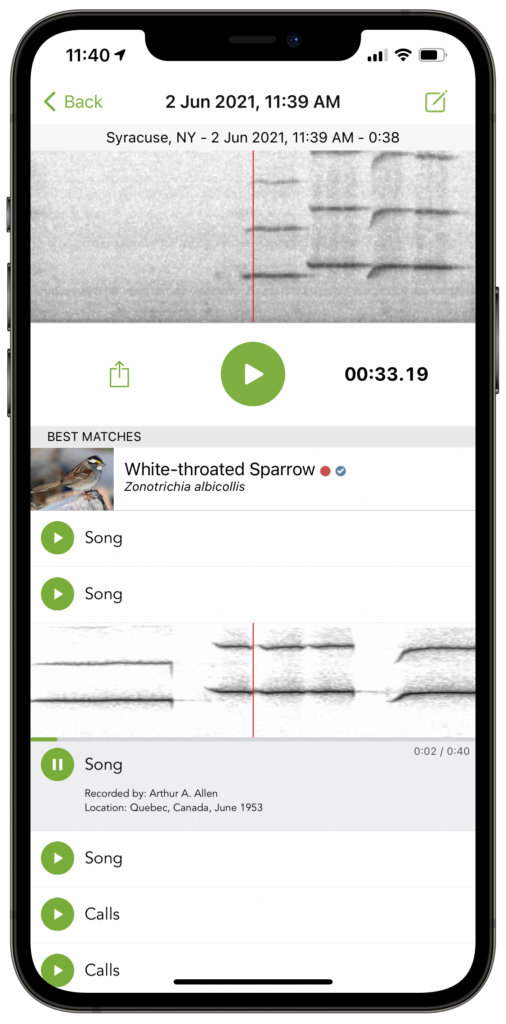
How does Sound ID work?
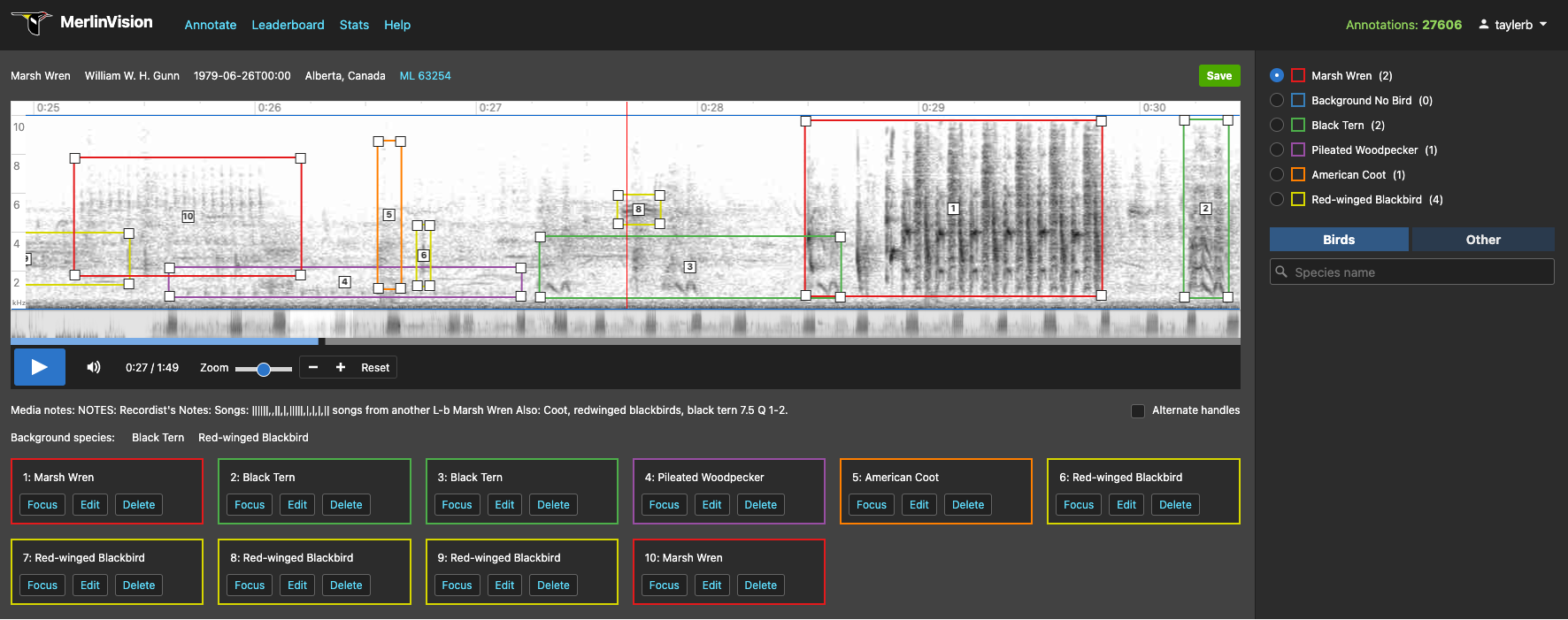
As your phone records sound, Merlin converts the audio into an image called a spectrogram. The spectrogram plots sound frequencies that appear in the recording, as a function of time. This spectrogram image is then fed into a modern computer vision model called a deep convolutional neural network. We trained this model to identify birds based on 140 hours of audio containing bird sounds, in addition to 126 hours of audio containing non-bird background sounds, like whistling and car noises. For each audio clip, a group of sound ID experts from the Macaulay Library and the eBird community found the precise moments when birds were making sounds, and tagged those sounds with the corresponding bird species. The model can use this detailed supervision from experts to learn how to correctly predict the species that appear in these annotated audio clips, with the goal of generalizing this knowledge to predict which birds appear in audio recordings it hasn’t heard before.

So how does it work? Once the database of sounds is assembled, we train the computer vision model using a gradient descent algorithm. When the model “hears” a sound clip, it makes a prediction that is based on the transformation of the sound clip’s spectrogram through a series of mathematical operations involving millions of numbers (called weights). The gradient descent algorithm figures out how to adjust the value of each weight to ensure that the model’s predictions match those of the sound ID experts. This weight updating process is the “learning” part of machine learning.
Building the sound ID model is an iterative process, involving a back-and-forth between the sound ID experts, members of the machine learning team, and people who provide feedback based on field tests of the app. After evaluating a trained model’s performance, we make adjustments to the training algorithm, ask the sound ID experts to label more audio clips, and try to locate any human errors in the previously labeled data.
What’s special about Sound ID in Merlin?
Merlin is not the first to use deep convolutional neural networks to identify birds by their sounds. In fact, Merlin draws inspiration from a number of other projects, including BirdNET and BirdVox.
There have been many other approaches to bird sound ID through the years, the result of engineering contests such as BirdClef and DCASE, among many others. Similar techniques have been used to monitor the activity of bats, as well as find patterns in whale songs.
Previous bird sound ID models have typically been trained using data with a coarser level of temporal resolution. For instance, a model might hear a 30 second recording of a White-breasted Nuthatch, but not be told when the nuthatch is singing in the recording. This can lead to problems: if other species are singing in the same recording, the model will erroneously call all species in the recording a White-breasted Nuthatch, leading to false predictions.

Merlin’s Sound ID tool is trained using audio data which includes the precise moments in time when each bird is vocalizing. The process of generating this data is labor intensive, because it requires sound ID experts to listen to each audio file carefully. As a result of these efforts, the model has the opportunity to learn a more accurate representation of which sounds correspond to which species (and which sounds are ambient noises). Recent research confirms that temporally fine-grained labels can help improve audio classification performance.
What’s next?
In building the model, we made a number of design decisions about how to handle our particular dataset, how to integrate predictions with information from eBird (a database of bird sightings shared by citizen scientists from around the world), and how to maximize the accuracy of Merlin Sound ID’s predictions in the field.
In the coming weeks, we’ll be posting a series of articles that take a closer look at these design decisions. We’ll also explore some of what’s in store for our Sound ID tools in the future.
If you’ve tried Sound ID in Merlin, we’d love to hear about your experience. You can get in touch on Twitter, where the Macaulay Library is @MacaulayLibrary.